AI-Powered Network Monitoring
From Reactive Troubleshooting to Predictive Intelligence
6 Minute Read
As networks grow more dynamic, distributed, and mission-critical, threshold-based monitoring — static rules, manual diagnostics, and per-domain dashboards — is no longer sufficient. Operators need a paradigm shift from reactive firefighting to predictive, AI-driven intelligence that protects uptime, performance, and security across hybrid infrastructures.
Traditional monitoring tools often fall short because they rely heavily on predefined rules and human intervention. This approach creates significant challenges for IT teams, beginning with alert fatigue. Thousands of false positives can overwhelm staff, making it difficult to distinguish genuine issues from noise. Slow root-cause analysis further complicates matters, as manual correlation across logs, metrics, and flows delays resolution. Blind spots also emerge when siloed tools fail to capture cross-domain dependencies in hybrid cloud, IoT, and remote work environments. Ultimately, this results in a reactive posture where problems are addressed only after they impact users or service-level agreements.
Reactive troubleshooting often blindsides IT teams with failures, forcing diagnosis under pressure. Conventional tools provide limited visibility, flagging problems only after performance has already degraded. Teams are burdened with data overload, struggling to interpret fragmented real-time information and spot early warning signs. Scheduled maintenance can also waste resources, leading to unnecessary downtime or part replacements.
AI-powered monitoring platforms offer a transformative advantage by shifting from noise to actionable insight. Through machine learning, time-series forecasting, and anomaly detection, these systems establish dynamic baselines that define what "normal" looks like across traffic, latency, and error rates. They suppress false alarms by filtering out benign deviations, predict failures before they escalate, and accelerate root-cause analysis with dependency mapping and AI-guided diagnostics. This evolution allows IT teams to focus on prevention rather than simply reacting to issues after they occur.
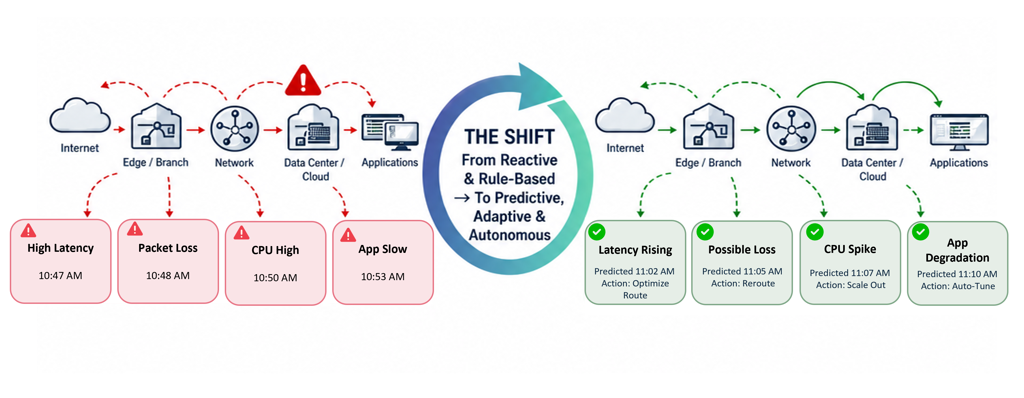
Predictive intelligence enables anomaly detection by identifying deviations from normal baselines in real time. It applies predictive analysis, training algorithms on historical data to recognize subtle warning signs that precede failures. Automated troubleshooting pinpoints root causes and initiates remediation steps, minimizing manual intervention. By predicting and preventing failures, AI improves efficiency, reduces operational costs, and frees staff for more strategic work. The result is enhanced reliability, with more resilient networks that minimize disruptions and improve customer experience.
Modern AI platforms also enable unified observability across the classic three pillars (metrics, logs, traces), extended with packet- and flow-level visibility. Metrics such as CPU, memory, and throughput are correlated with logs from system, application, and security sources; traces capture transaction flows across services; and packet/flow records add the network-layer visibility that observability stacks borrowed from monitoring. This cross-layer integration delivers holistic insights and contextual alerts. Gartner has forecast that by 2026, 70%+ of enterprises will have implemented observability as a core operational capability — a useful signal, but operators should treat the figure as directional, not prescriptive.
The real-world applications of AI-powered monitoring are already evident. Proactive outage prevention becomes possible when anomalies in traffic patterns are flagged before thresholds are breached. Security enhancement is achieved by detecting unusual flows or access patterns that may signal intrusions. Capacity planning benefits from forecasting tools that optimize bandwidth and resource allocation. Self-healing networks represent another frontier, where agentic AI can reroute traffic, restart services, or adjust policies automatically — moving the operator up the TM Forum Autonomous Networks ladder (L3 conditional automation → L4 high autonomy, per TR-178 / IG1230). Dynamic traffic allocation further strengthens performance by adjusting bandwidth in real time to prioritize critical applications.
Successful implementation requires sequencing. Operators should begin with high-impact, high-frequency domains (RAN cell-availability, transport link-state, core SBA signaling) where ground-truth and incident volume are sufficient to train and validate models. Integration with existing network management and operations support systems is essential, using APIs to ingest telemetry and trigger workflows. Training models on localized data ensures context-aware performance, while explainability remains critical. Platforms must translate AI insights into plain-English diagnostics so operators can act quickly and confidently.
Challenges include the dependence of predictive models on accurate and complete data, since poor inputs can undermine outcomes. Many organizations face difficulties integrating AI with legacy systems that are not natively compatible, requiring strategic planning and investment. A lack of skilled personnel in data science and machine learning can slow adoption, making training or new hires necessary. Trust and transparency also remain obstacles, as AI's "black box" nature can hinder operator confidence — which is why explainability, confidence scoring, and human-in-the-loop approval gates are required before any agentic action reaches production change windows. Finally, the high initial cost of advanced AI monitoring tools can be substantial, though long-term savings from improved efficiency and reduced downtime often offset this investment.
AI will continue to drive network management toward fully autonomous and self-optimizing systems. With AI-enabled workflows, networks will become more resilient, efficient, and secure. Over time, AI will adapt dynamically to changing conditions, predict and rectify service degradations before they occur, and automate an increasing number of tasks. IT teams will shift focus from firefighting to strategic, high-value initiatives.
Ultimately, AI-powered network monitoring represents more than a technical upgrade — it is a strategic imperative. By reducing mean time to repair and downtime costs, enhancing user experience through consistent performance, and strengthening security posture with early threat detection, organizations can scale operations without proportionally increasing headcount. This shift from reactive to resilient monitoring positions enterprises to thrive in an increasingly complex and interconnected digital landscape.
By embracing predictive intelligence, telecom operators and enterprises can move beyond reactive troubleshooting and toward resilient, self-optimizing networks aligned with TM Forum AN Level 4 (highly autonomous) operating models.